//赫夫曼节点,用于构成赫夫曼树 type HuffmanNode struct { Weight uint//权重 Data interface{} //数据 Parent *HuffmanNode //父节点 Left *HuffmanNode //左孩子 Right *HuffmanNode //右孩子 }
//给定一组字符及其权重的集合,初始化出一棵赫夫曼树 funcNewHuffmanTree(src map[interface{}]uint) *HuffmanTree { var tree = &HuffmanTree{ src: src, } tree.init() tree.build() tree.parse() return tree }
//根据数据进行赫夫曼编码 func(h *HuffmanTree) Coding(target interface{}) (result string) { if target == nil { return } var s string switch t := target.(type) { casestring: s = t case []byte: s = string(t) default: return } for _, t := range s { v := string(t) if c, ok := h.codeSet[v]; !ok { panic("invalid code: " + v) } else { result += c } } return result }
//根据赫夫曼编码获取数据 func(h *HuffmanTree) UnCoding(target string) (result string) { node := h.root for i := 0; i < len(target); i++ { switch target[i] { case'0': node = node.Left case'1': node = node.Right } if node.Left == nil && node.Right == nil { result = result + node.Data.(string) node = h.root } } return }
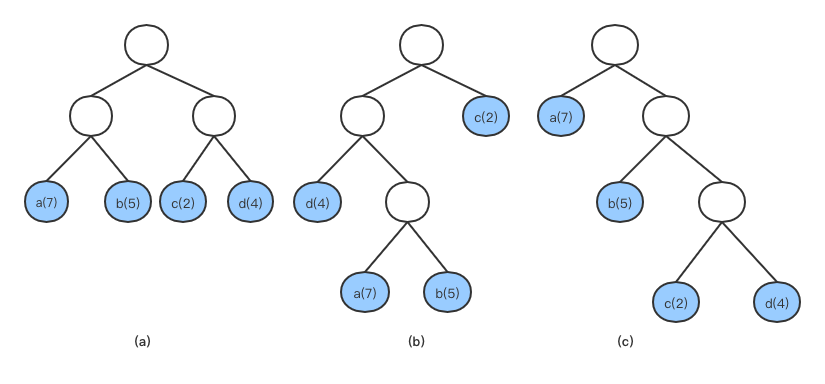
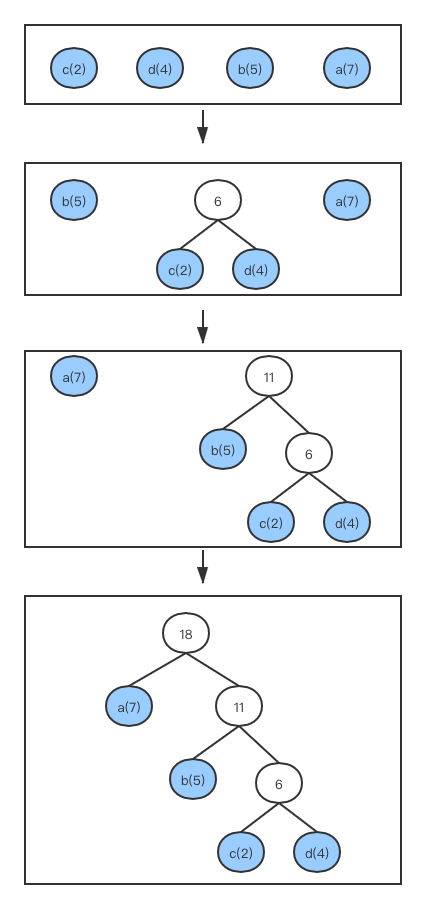
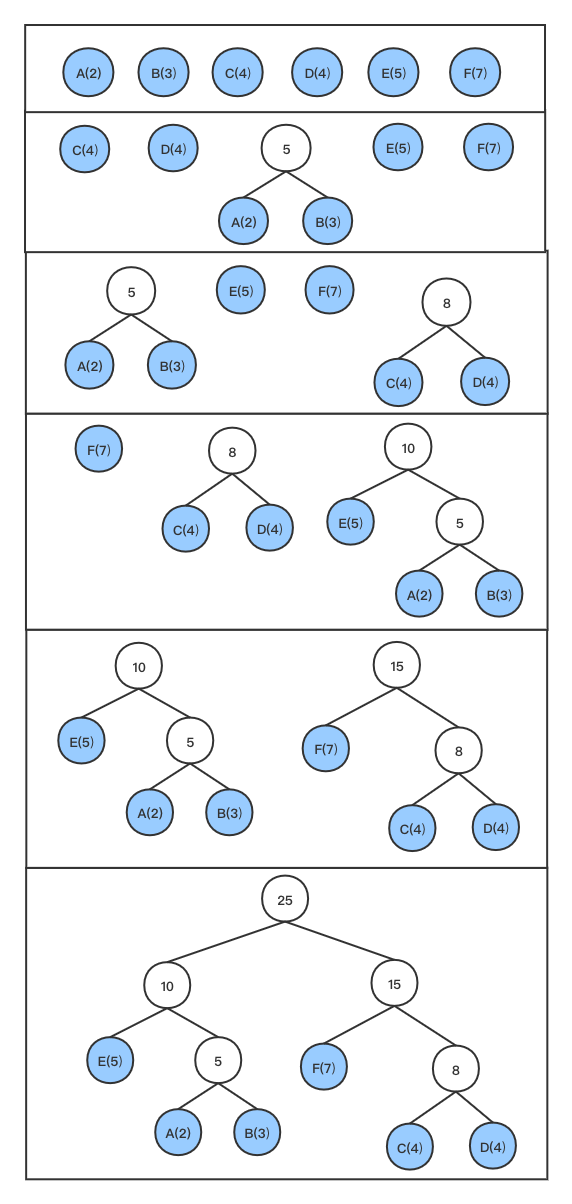
//初始化所有叶子节点 func(h *HuffmanTree) init() { iflen(h.src) <= 1 { panic("invalid src length.") } h.codeSet = make(map[interface{}]string) h.leaf = make(HuffmanNodeList, len(h.src)) var i int for data, weight := range h.src { var node = &HuffmanNode{ Weight: weight, Data: data, } h.leaf[i] = node i++ } //对leaf根据权值排序 sort.Sort(h.leaf) }